Como visto em Paradigmas estéticos para classificar imagens informacionais primeiramente, trabalhou-se na classificação cognitiva da amostra inicial de 6.000 imagens, nas categorias Factual, Memes, Ilustração digital, Tipografia digital, Ilustração manual, Tipografia vernacular e Apropriação. Essa classificação inicial foi usada como referência (target) para o treinamento e aprendizagem da máquina supervisionada (supervised learning) na criação de cinco rotuladores de imagens (labels). [Sidenote: As estratégias e decisões acerca dos modelos utilizados para essa etapa de trabalho, assim como o protocolo desse processo de trabalho foram realizados em conjunto com o cientista de dados e então aluno da POLI-USP e pesquisador do Inova USP, Gustavo Polleti.] Construímos seis bibliotecas de dados incluindo seis targets (imagens com atributos para treinar a máquina em cada categoria).
A aplicação de uma estratégia metodológica baseada em uma análise qualitativa a partir de uma amostra quantitativa de uma grande quantidade de imagens, resultou em uma amostragem e uma classificação significativa para o objetivo proposto. A inteligência artificial foi aplicada como ferramenta criativa no processo de arquivamento, edição e visualização das narrativas, desde a captação das imagens, visualização e rotulação, até a catalogação como acervo da memória gráfica brasileira, como pode ser visto no Calendário Dissidente.
O processo de design dos códigos para treinamento e aprendizagem de máquina supervisionada com o objetivo de visão computacional para fins estéticos de reconhecimento de determinada linguagem visual foi, até onde pudemos apurar, um procedimento inédito. Um experimento que tinha uma demanda do campo do design gráfico e exigia conhecimentos da ciência de dados para ser realizado. Esta experiência colaborativa também foi desenvolvida durante a residência no Inova USP.
O uso de AI e aprendizagem de máquina para a classificação dessa superprodução de imagens dissidentes mostrou-se fundamental por três motivos: o primeiro, para auxiliar na classificação dessa amostragem quantitativa muito grande; o segundo, para desmistificar as inteligências artificiais como uma “caixa preta”, abrindo a possibilidade de uso de novas ferramentas para a visualização de narrativas de imagens. E o terceiro e mais importante, diz respeito à subjetividade da atividade de classificação, seja ela humana ou algorítmica. A interpretação de uma imagem feita por rotuladores é matemática. Porém, a interpretação dessas imagens pelas IAs também apresenta traços de subjetividade, herdados da classificação humana dos modelos de treinamento. Os pontos críticos da decisão entre uma categoria ou outra acontecem tanto na categorização cognitiva, feita por humanos como na leitura dos classificadores da rede neural.
Paralelamente ao processo tecnológico da criação dos rotuladores, problematizamos a visualização de dados, o engajamento de grupos e uso de bots e algoritmos para constatar a estandardização (ou proliferação) de linguagem das imagens das redes a partir de Manovich (2018).
Em Estéticas da inteligência artificial, Manovich (2018) aborda a importância do uso criativo da aprendizagem de máquina supervisionada como uma excelente ferramenta para designers, artistas e pesquisadores. O autor propõe quatro taxonomias para entendermos o potencial da cultura digital e o uso de inteligência artificial:
(i) selecionando conteúdo de grandes coleções;
(ii) segmentando e objetivando a extração de conteúdo: marketing personalizado/público – viés comercial;
(iii) assistindo à criação/edição de conteúdos ou participação na criação de conteúdo;
(iv) criando obras totalmente autônomas (compondo músicas, faixas, escrevendo, criando visualizações a partir de determinados conjuntos de dados).
Nesse estudo, a inteligência artificial está sendo aplicada na seleção e classificação de uma coleção de imagens (i) assim como na criação de conteúdos específicos a partir dos seis parâmetros curatoriais (iv). O autor nos provoca a questionar nossa responsabilidade como criadores de classificações e rótulos. Concordamos com Manovich (2018) sobre a responsabilidade dos parâmetros e escolhas das imagens selecionadas como modelo para a aprendizagem de máquina. Essas são a medida para que a inteligência artificial opere mais qualitativamente. Pudemos verificar esse fenômeno na prática quando observamos como as restrições e potencialidades dos robôs são similares às dos humanos.
Damos continuidade à discussão sobre o uso criativo e disruptivo e novas estratégias para visões computacionais por meio das obras expostas na galeria Uso de IA para fins artísticos e curatoriais. São trabalhos realizados por artistas e pesquisadores – Paglen (2018), Moreschi (2018), Beiguelman (2022), Velazquez (2021), entre outros – nos quais discute-se os vieses políticos e tendenciosos das classificações e dos treinamentos por um viés cultural, decolonial e social.
Estandardização e escolhas algorítmicas
Sobre a estandardização da estética global das imagens que circulam nas mídias digitais, Manovich (2018) comenta que as inteligências artificiais são utilizadas por diversos aplicativos de fotografia disponíveis para download por qualquer usuário. Esses apps fornecem tags e parâmetros relacionados ao tipo de foco, filtros de cor, composição, além de tagueamentos como “retrato”, “comida”, “paisagem”, etc. Tais modelos, previamente disponíveis para o usuário “plug and play”, acabam automatizando e sugerindo padrões estéticos pré-estabelecidos – “the stardardization of photo imagination” (GRIGONIS, 2016; apud MANOVICH, 2018).
Por outro lado, há cada vez mais aplicativos e sites para diferentes mídias que permitem a customização dos serviços. A inteligência artificial, neste caso, aumentou a diversidade dessas funções e essas mudanças de algoritmo, cada vez mais presentes nas redes e em outras mídias. Ela permite uma variedade de combinações infinitas. O Instagram, por exemplo, usa datasets (conjunto de dados programados para exercer determinadas funções e comportamentos) que determinam a visualização das imagens: os posts são programados para serem visualizados primeiramente dentro do círculo de seguidores com os quais o usuário mais interage, ou seja, dentro da sua “bolha” de amigos que interagem com o mesmo tipo de notícia, etc. A experiência do usuário, dos compartilhamentos, dos likes e dos engajamentos das repostagens é moldada pela experiência visual restringida pelos filtros algorítmicos do aplicativo. Pesquisando, por exemplo, por #designativista, o que uma pessoa vê em seu feed como “top posts” é diferente do que outra pessoa que não pertence ao mesmo grupo de seguidores vê, conforme demonstra a figura abaixo.
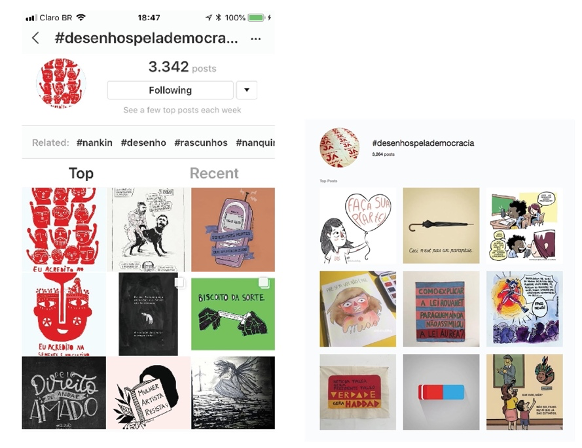
Ou seja, a visualização institucional do Instagram está programada para que o usuário veja primeiramente imagens de amigos e amigos de amigos, que, de certa forma, têm mais afinidade estética com as escolhas da pessoa usuária. Esse ambiente “fechado” e manipulado age como um vírus, um “contágio”, compreendido em um léxico de linguagem visual, incentivando a produção de outras peças gráficas que seguem a mesma estética “coletiva”. Um esquema já foi criado por alguém, e, posteriormente, apropriado e remixado. Portanto, cria-se um padrão visual identificatório, do qual seus pares, seguidores, amigos e familiares se sentem representados. Há um conforto estético, algo “estranhamente familiar” – para citar uma expressão freudiana, na medida em que os elementos visuais, as cores e a tipografia remetem a algo revisitado, visto e revisto, já conhecido e presente no nosso inconsciente. [Sidenote: Ver O inconsciente estético de Jacques Rancière (2009, p. 12). O autor aplica a teoria freudiana do inconsciente ao domínio da estética. E discorre sobre um modo de pensamento que se desenvolve sobre as coisas da arte “que procura dizer em que elas consistem enquanto coisas do pensamento”.]
Para ampliar a amostra qualitativa da produção cultural, mostrando a diversidade da produção nacional, precisamos buscar as diferenças, o que está fora da curva, o novo, em uma amostragem abundante. Portanto, redundância, repetição de imagens e quantidade foram bem-vindos nesse estágio da pesquisa.
Trabalho com os classificadores de imagem
Os classificadores de imagem visam discernir entre um conjunto pré-definido e finito de rótulos, qual o mais apropriado para uma dada figura no Instagram. Em função da subjetividade inerente às classes abordadas neste trabalho, é difícil criar um algoritmo ou método objetivo capaz de realizar a tarefa de classificação por completo. No caso desta investigação o uso de scripts open sourcepara classificadores de imagens agilizou o processo de criação e customização dos “classificadores dissidentes”.
A partir dos dados coletados e rotulados na etapa anterior, iniciamos o treinamento supervisionado de modelos de aprendizagem de máquina (machine learning). Partimos de testes usando técnicas de aplicação de modelos de aprendizagem profunda (deep learning) em redes neurais profundas – essas têm como objetivo aprender as representações latentes e poder identificar alguns padrões “ocultos” nos dados (KRIZHEVSKY et al., 2012).
A rede neural convolucional, a arquitetura selecionada para este trabalho, é projetada para considerar referências espaciais e de localidade, de modo que a proximidade entre os pixels seja aferida. Os modelos da convolutional neural network (CNN) são notavelmente recomendados para estudos de visão computacional, como a classificação de imagens (Ibid, 2012). Estes modelos visam aprender representações a partir dos dados brutos.
A etapa de configuração e processamento dos algoritmos é realizada automaticamente, como parte do próprio aprendizado da máquina. Estas operações são conhecidas por sua capacidade de considerar padrões complexos, como em classificação de imagens, o que as torna apropriadas para o estudo de caso (LECOUTRE et al., 2017). Com tal metodologia, pudemos apurar numericamente o comportamento dos rotuladores, seus acertos e erros.
Para complementar a avaliação da acurácia dos seis rotuladores (labels), realizamos a análise da Matrix de confusão (confusion matrix). Nessa etapa, verificamos que precisaríamos de outra metodologia e de outro modelo para a criação do classificador de apropriação, pois o banco de imagens de treinamento exigiria uma ampla pesquisa das referências visuais originais.
Análise quantitativa dos classificadores: acurácia
A criação dos modelos de classificação foi realizada no sistema computacional Python 3.7. Utilizou-se primeiramente, modelos e bibliotecas de classificadores de imagens disponíveis como “open source”, e implementamos os modelos de linha Logistic Regression (LR) e Random Forest (RF). Em seguida, avaliamos os dois modelos para precisão, conforme mostrado na figura abaixo. LR e RF tiveram um desempenho ruim, atingindo menos de 35% de precisão.
Visualização das métricas das acurácias dos classificadores (em todas as categorias):
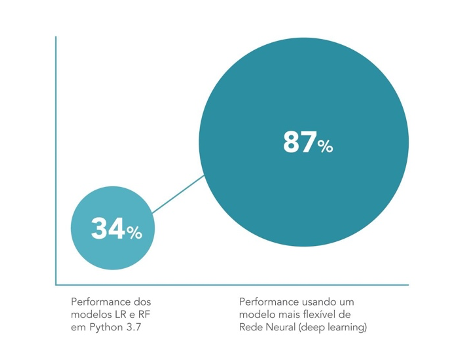
Na prática, esses modelos fazem a leitura dos pixels das imagens, detectando se compõem fotografias, desenhos vetoriais, tipografias. A leitura é realizada por micro pixels, de modo que uma fração mínima é interpretada, criando parâmetros horizontais e verticais de leitura para a configuração do todo da imagem. Esses resultados sugerem que os modelos iniciais estavam mal equipados, ou seja, não foram capazes de capturar efetivamente os padrões sutis que descrevem nossas classes estéticas. Além disso, o fraco desempenho de nossos modelos de linha de base apontou para a necessidade de um modelo mais flexível, como os do deep learning (aprendizagem profunda). Os modelos flexíveis conseguem fazer correlações de mais detalhes das imagens para transformá-las em dados classificatórios. Esses modelos interpretam mais profundamente a leitura das imagens utilizadas na aprendizagem da máquina, melhorando a acurácia da classificação.
Parâmetros dos classificadores
As representações resultantes da aprendizagem da máquina capturam dados e informações relevantes que supostamente estão ocultas. Dessa maneira, a classificação será realizada usando abstrações de alto nível de detalhes da imagem, em vez de pixels, por exemplo. Apesar de altamente precisas, as previsões baseadas nessas representações não são interpretáveis, pois os padrões significativos para a máquina podem não ser vistos pelo olho humano. De fato, essas são modeladas sem um hiperespaço, onde as dimensões não têm significado explícito ou semântico.
Para melhor identificação dos padrões das imagens, implementamos um modelo da CNN que consiste em duas camadas convolucionais. Assim, nossa estrutura consistiu em 128 neurônios organizados em duas camadas de leitura de dados.
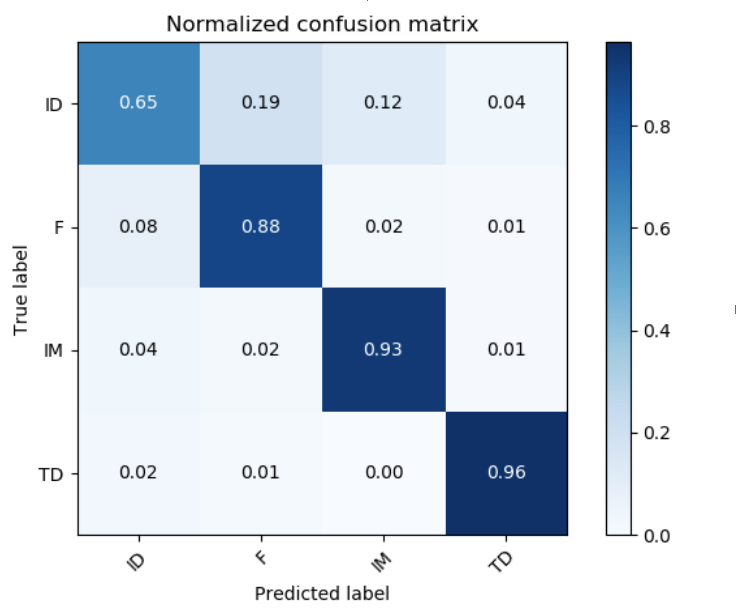
Em seguida, avaliamos nosso modelo na coleção das imagens em termos de precisão. Os resultados estão apresentados na figura abaixo. Observa-se que a acurácia usando rede neural convolucional superou os modelos iniciais de linha de base (sem rede neural). Além disso, analisando a matriz de confusão, pode-se observar que nosso modelo conseguiu classificar adequadamente todas as categorias.
Ao observar as imagens classificadas pela inteligência artificial, percebeu-se a dificuldade da interpretação relacionada às ilustrações, em geral. A categoria Ilustração digital é confundida com a Factual e também com Ilustração manual. Discutiremos essa questão adiante, a partir da interpretabilidade e visualização dos dados.
Embora os métodos de avaliação baseados nas métricas quantitativas de acurácia ofereçam uma visão clara da performance do classificador, reforçamos o fato de que não basta fornecer uma interpretação completa do comportamento do modelo (KIM, 2016).
Com o propósito de visualizar o significado desses números, a autora insistiu na busca de outros modelos de tradução de números em visão computacional, mais palpáveis para um editor de imagem e designer. Buscou-se técnicas de interpretabilidade para complementar a análise e explicar por que o modelo é mais propenso a confundir uma classe por outra.
A interpretação dos classificadores de imagens
Para atender à necessidade de uma análise mais qualitativa, propomos o uso de método crítico de visualização de dados, que pode ser considerado como a tradução do número à imagem, uma ferramenta de visualização para que um cientista de dados, designer, editor ou artista possa entender melhor o comportamento dos rotuladores.
Em Examples are not enough, learn to criticize, Been Kim (2016) descreve a relevância do modelo “MMD Critic”, software livre (open source) disponibilizado pelos autores, pesquisadores do MIT Lab. O modelo possibilita a visualização da interpretação da máquina e evidencia quais as imagens críticas – cujos elementos visuais não permitem sua classificação em determinada categoria. Essa informação é um dado fundamental em relação às limitações e aos erros dos classificadores de redes neurais. Os autores levantam, ainda, a importância da visualização das imagens críticas como apoio à interpretação humana em relação às limitações e aos erros dos classificadores de redes neurais (KIM et al., 2016). Esse modelo busca identificar simultaneamente quais imagens, em determinado contexto, são representativas de toda a coleção (protótipos) e quais diferem das demais (críticas), pois não conseguem ser interpretadas por falta de um padrão predominante.
Ao aplicar esse modelo em todas as categorias, podemos afirmar que a visualização dos protótipos e a análise das imagens críticas permitiram insights sobre os padrões estéticos utilizados para o treinamento dos modelos de aprendizagem de máquina. Ainda, observa-se que essas imagens geradas pela máquina, revelam um outro tipo de imagem digital, outra narrativa que representa a “narrativa visual das máquinas”, a partir do que realmente é lido e interpretado por elas.
Análise qualitativa dos resultados
Classificar grandes quantidades de imagens e descobrir novas tendências estéticas é uma atividade interdisciplinar na qual os erros e acertos enunciam a fragilidade da rede neural em definir métricas para categorias estéticas. A representação visual das métricas quantitativas também é fundamental no processo de aprendizagem da máquina.
Com o objetivo de analisar a margem de 13% de erro na acurácia dos classificadores do projeto, buscou-se soluções para a visualização do processo de classificação e o porquê do erro. Na amostragem usada para o treinamento, havia imagens que poderiam ser enquadradas em mais de uma categoria. Já era presumida a complexidade do projeto em reconhecer essas imagens, compostas por linguagens híbridas. O processo de tangibilização desses índices por meio da visualização das imagens possibilitou a identificação visual dos acertos e dos erros na classificação. O dado quantitativo passa a ter um valor qualitativo à medida em que ele enuncia quais imagens são mais representativas dos acertos e dos erros dos classificadores.
A imagem visualizada pelo robô
Nas imagens abaixo observa-se a visualização das seis categorias com a resolução de 120×120 pixels. A acurácia visual para o olho humano é surpreendentemente boa. Textos e detalhes de imagens podem ser facilmente reconhecidos. Ou seja, existe uma interdependência entre a acurácia da leitura da máquina e a acurácia do olho humano. Curiosamente, as imagens de leitura “crítica” para a rede neural são justamente as imagens nas quais há uma sobreposição de técnicas: desenho manual, foto recortada, colagem digital, tipografia manuscrita.

As questões subjetivas do treinamento da máquina não são abertas ao público. O usuário de um serviço de visão computacional tem acesso apenas ao resultado final de determinado classificador. No caso deste estudo, os pesquisadores participaram de todo o processo de treinamento e aprendizagem da máquina para a construção dos rotuladores. Inferiu-se exemplos visuais, muitas vezes de difícil reconhecimento formal devido à linguagem múltipla, remixada, inerente às publicações das redes. De fato, seria impossível ter certeza, empiricamente, sobre o pertencimento de uma imagem às categorias Factual ou Ilustração digital, como no exemplo da figura abaixo:

A imagem acima é composta por múltiplas linguagens: a fotografia de um índio é recortada e trabalhada junto à outra fotografia de folhas de bananeira. Ao fundo, grafismos vetoriais aludem às pinturas étnicas. A imagem original foi interpretada pelos editores como Ilustração digital, pois utiliza-se de técnicas de remixagem incluindo uma fotografia documental. O fato de a fotografia (a figura central do índio) estar nítida tornou essa imagem crítica para o classificador, pois as fotografias documentais foram usadas para treinar o rotulador Factual.
As imagens da categoria Tipografia vernacular também foram apontadas como críticas por esse modelo. O que aponta para o fato de que o classificador se confunde e, na dúvida, também descreve essas imagens como críticas.

Após esta análise, decidiu-se não habilitar o rotulador referente à Tipografia vernacular. Já se sabia que a interpretação dessa categoria é subjetiva, pois considera-se aspectos culturais, regionais e etnográficos para classificar o estilo manuscrito das tipografias e caligrafias manuais. São composições híbridas com diferentes materialidades e resultam em uma linguagem remixada, impossível de ser detectada pela máquina.
Ao eliminarmos a categoria Tipografia vernacular, o desempenho dos classificadores saltou de 77% para 84%. Portanto, definiu-se que seriam utilizados rotuladores para Factual, Ilustração digital, Ilustração manual e Tipografia digital. Nestas categorias, as características formais dos posts não dependem do repertório cultural do treinador e editor para serem classificadas.
Classificadores estéticos, scripts creative commons
A partir de todo o contexto sociocultural, político e tecnológico envolvido no processo de utilização de inteligência artificial e aprendizagem de máquina – desde o treinamento dos sets de classificação das imagens, na nomenclatura das categorias, e sobretudo nas políticas de visibilidade dos dados – pudemos compreender a complexidade envolvida na criação de classificadores de imagens propostos nesta pesquisa. Esses, pensados para uma função classificatória bem mais específica (sem fins comerciais ou de vigilância), sofrem analogamente das mesmas dificuldades interpretativas dos seus treinadores.
O propósito da construção dos classificadores em questão pretendia investigar as novas linguagens visuais emergentes das redes, ampliando a amostragem quantitativa. Os parâmetros selecionados para o treinamento dos classificadores se basearam em critérios estéticos. Foram muitas etapas de treinamento e ajustes de modelos para enfim, concluirmos que a ferramenta criada para rotulagem das cinco categorias apresentou uma acurácia de 87%. Este modelo final, desenvolvido exclusivamente para esta pesquisa pelo cientista de dados Gustavo Polleti (Inova USP), gerou scripts open source e estão disponíveis para outras investigações ou produções artísticas nas bibliotecas on-line.
A análise qualitativa dessas imagens e o reconhecimento de algumas tendências e padrões gráficos foram enriquecidos pela amostra quantitativa, pelo uso de inteligências artificiais e pela visualização da acurácia e das dúvidas dos rotuladores. Com a visualização das classificações, foi possível aferir o que merece ser arquivado à luz do design gráfico, como uma nova linguagem visual inerente às redes sociais e como memória gráfica brasileira. Cabe aos designers usarem novas estratégias de visualização de dados a nosso favor.
Embora a subjetividade da classificação seja reconhecida e explicitada, assumiu-se o uso da inteligência artificial como uma ferramenta de apoio curatorial. O resultado bruto da classificação nas categorias propostas não poderia ir ao público sem passar por um filtro de edição e ainda, por uma releitura e análise visual. Nesse sentido, o projeto experimental dos classificadores não foi integrado e publicado ao grande público no site do Calendário Dissidente. Mas foi de suma importância no alargamento dos horizontes a respeito do que se produz nas redes, adicionando uma ferramenta importante para discutirmos as linguagens dessas imagens por um viés mais semântico, assunto a ser tratado em Análise semântica pela cultura do design.
Visões computacionais X ativismo
Como vimos, as imagens visualizadas por meio da estética de banco de dados e extração de coleções de imagens por meio de determinadas hashtags para fins de pesquisa e análises visuais apresentam um lado da moeda da visão computacional.
As políticas de visualização de dados relacionadas às imagens nas grandes plataformas têm uma lógica bem diferente do rastreamento algorítmico, por meio de palavras escritas. O treinamento das máquinas para a leitura de imagens requer uma biblioteca mais robusta acerca de parâmetros de reconhecimento das imagens e um conjunto de informações que dependem de ações humanas para a descrição textual das imagens. A subordinação da palavra sobre a imagem depende do olho humano para classificar as imagens. E é precisamente durante esta classificação de imagens que se dá todo o colonialismo das visões computacionais das grandes nuvens, as GAFAM, já apresentadas anteriormente.
O serviço de nuvens está incorporado em várias situações cotidianas de um cidadão portador de um smartphone. Ele utiliza redes sociais, serviço de e-mail e WhatsApp, se locomove utilizando aplicativos de geolocalização como Waze ou Move It, paga suas contas de energia, água, aluguel e impostos pela internet banking, contrata um serviço de backup como o Google Drive ou Dropbox para armazenamento de dados pessoais e trabalha em arquivos compartilhados, guardados em nuvens-servidores no espaço. Todos esses dispositivos são considerados nuvens informacionais e estão organizados por camadas distintas de nuvens de armazenamento e troca de dados – administradas por empresas e instituições privadas ou públicas – e estão fortemente conectadas com a cidade, com serviços e com a mobilidade urbana.
Tais aspectos da mobilidade urbana podem ser compreendidos no pensamento de Castells (1999) antes desta realidade. O autor atribui ao Espaço de Fluxo, a criação de uma nova forma urbana: a cidade informacional “na qual uma série de transformações sociais, econômicas e políticas, potencializadas pelas tecnologias de informação e comunicação, têm prenunciado novas formas de interação do cidadão com o espaço urbano” (CASTELLS, 1999). O conceito de nódulo também é apontado pelo autor como o ponto de encontro no qual estão todas as instituições públicas e privadas que detém todos os dados que circulam no fluxo.
Benjamin Bratton (2015) atualiza alguns dos conceitos introduzidos por Castells em The stack: on software and sovereignty. A partir de um viés mais econômico, tecnológico e informacional, definido pelo autor como “capitalismo-plataforma de nuvens”. Ainda aponta que o grande desafio da contemporaneidade é que independente da geografia, a nuvem alcança qualquer lugar, constrói outros lugares (territórios desconhecidos, pois apaga geografias e constrói outras). Uma nova geografia constituída por redes e fluxos em diversos patamares/ou andares.
Curiosamente o sistema da nuvem informacional está presente acima e debaixo da terra. Formam camadas de troca de dados, constrói mundos e cartografias, habita novos territórios muito além dos lugares onde fazemos nossas atividades cotidianas. Conforme aponta Bratton, elas ocupam espaços transurbanos, excedem o conceito de lugar e fronteiras, são espaços de fluxos. Essas nuvens configuram as Cloud Polis e operam em uma camada intermediária sob as cidades, pois habitam um local nem virtual, nem real.
Esta configuração gera uma outra dinâmica mundial, novas divisões de poderes em novas “polis” que independem dos Estados para funcionarem, existirem e se constituírem em novas cartografias de rede. Essa análise de Bratton é esclarecedora para entendermos a dicotomia dessas nuvens que são terrenas, materializadas em grandes data centers –espalhados em lugares estratégicos no globo – e conectados por grandes cabos de fibra óptica (enterrados na terra).
Os designers e ativistas Daniël van der Velden e Vinca Kruk, do estúdio Metahaven, alfineta a opacidade dessa nuvem: “O Google, uma das sete maiores cloud companies, se comparou a um banco. Se os dados na nuvem são como dinheiro no banco, o que acontece com ele enquanto reside convenientemente na nuvem?” (METAHAVEN, 2012). A dupla observa um fenômeno interessante em relação aos usuários das redes: o senso de abstração sobre as nuvens, responsável por fazer com que os usuários (e dependentes das nuvens) fiquem cada vez mais tranquilos com seus dados guardados nas nuvens de algodão, dormindo como carneirinhos. E assim tornam-se cada vez mais resilientes à obscuridade do fluxo e armazenamento de seus dados pessoais nessas nuvens.
Ou seja, o usuário não precisa ou não quer entender o funcionamento de dentro da nuvem (do software ou aplicativo), onde seus dados estão. A coisa mais importante é que a nuvem funcione.
Vale mencionar que os serviços da nuvem Google vão além das buscas algorítmicas numéricas e alfabéticas e investe em serviços e aplicativos de visualização de imagem. O Google Cloud Vision é uma potente ferramenta de visão computacional que, por meio de aprendizagem de máquina, investiu no reconhecimento e rotulação de imagens com inteligências artificiais. A estratégia vai muito além do que é oferecido no Google Lenz – lançado para uso doméstico em 2018 – na medida em que todo o plano de negócios da empresa gira em torno da comercialização desses dados rastreados e tagueados, visando potenciais anunciantes.
A identificação de imagens e o aprofundamento do significado do que não se sabe (nesse caso, do que não se vê com o olho humano), ganha uma extensão a partir desse aplicativo que interconecta imagem com o significado do objeto. O aplicativo permite conectar a imagem ao seu nome científico, ou descrição textual, numa combinação de dados numéricos e alfabéticos e visuais sem precedentes. O serviço é oferecido como parte do Google Assistant ou nas câmeras dos celulares com sistema Android, quando o aparelho está conectado com uma rede. [Sidenote: Informações extraídas do artigo de Lauren Gear When in nature, Google Lens does what the human brain can’t, publicado em 27 de junho de 2018. In https://www.wired.com/story/google-lens-does-what-the-human-brain-cant/: acesso em 30 de junho, 2018.]
Esse tipo de serviço vislumbra uma nova era de reconhecimento e busca de imagem de banco de dados na qual os dados visuais são associados a outros dados contextuais e talvez represente nesse momento um novo paradigma da era dos dados, no qual as imagens passam a ser interpretadas, clonadas e associadas com outros pares de imagens a partir de rótulos, tags, evidências de repetição que alimentam as redes neurais e treinam “o olho da máquina”.
Em Interrogating vision APIs (MINTZ e SILVA, 2019), os autores abordam as limitações das leituras dos serviços de visualização computacional do Google, IBM e Microsoft. Por meio de uma coleta de imagens acerca do mesmo termo, em diferentes países, o estudo apresenta as dificuldades de interpretações relacionadas às políticas socioculturais locais e os parâmetros estandardizados globais usados por esses classificadores de imagens.
O viés colonialista e comercial das visões computacionais também pode ser observado nessa pesquisa, no estudo de caso das imagens extraídas pela #mariellepresente e submetidas às leituras da visão computacional do Google, conforme detalharemos a seguir.
O argumento dos autores reforça a importância da criação e treinamento de classificadores de imagens específicos (e independentes) para a catalogação de determinados grupos de imagens. A visão computacional está sujeita à visão de mundo e ao repertório do treinador da máquina. Ou seja, modos de ver eurocentristas, muitas vezes racistas e colonialistas, muitas vezes vinculados aos vieses comerciais das ferramentas.
Como visto, para esta pesquisa, trabalhamos com alguns sets de imagens capturadas a partir de algumas hashtags ativistas. Esse conjunto de narrativas, pode ser visto no experimento gráfico Calendário Dissidente.
#mariellepresente: visão humana X visão computacional
No conjunto de imagens arquivadas e organizadas pelo software do Calendário Dissidente, podemos observar que #mariellepresente é a hashtag com maior número de postagens dentro do período da coleta de dados. Tiveram início com o seu assassinato em 14 de março de 2018 e, desde então, esse conjunto de milhares de imagens representam um contexto digital inédito, no qual há uma intensa disseminação de conteúdos politicamente engajados, relacionados aos ativismos aos quais a figura de Marielle representa.

No caso dessa hashtag, especificamente, essas imagens-mensagens relacionam-se a várias manifestações e a diversos eventos não exatamente relacionados à sua morte. Por um viés de análise semântica (JARDÍ, 2014) a figura de Marielle virou um ícone dos ativismos LGBTQIA+, racismo, empoderamento feminino, democracia, entre outros. E um símbolo de resistência, representado pela sua figura de mulher preta, lésbica, vereadora do Rio de Janeiro durante a gestão de Bolsonaro.
Os valores simbólicos da figura de Marielle mobilizam muitas narrativas nas redes sociais. São narrativas fragmentadas, relacionadas a alguma das várias lutas que de alguma forma estão relacionadas à sua imagem. Quando analisadas em conjunto, a partir da hashtag em questão, se potencializam, em um coro polifônico. No artigo Imagens da resistência: pensando sobre a visão computacional das inteligências artificiais e o capitalismo de vigilância pelas imagens de Marielle Franco [Sidenote: Artigo escrito em conjunto com Vinicius Ariel dos Santos, aluno da Escola Politécnica da Universidade de São Paulo (POLI-USP) e membro do Grupo de Inteligência Artificial (GAIA) do Inova USP. São também coautores os pesquisadores Bruno Moreschi (coordenador do GAIA e orientador de Santos), Amanda Jurno, Monique Lemos e Lucas Sequeira. (2022: Texto no prelo para o Journal digital culture & society: networked images in surveillance capitalism).] , tivemos a oportunidade de ampliar essa análise sob o ponto de vista do capitalismo de vigilância, exercido pelas grandes nuvens.
O viés de vigilância das visões computacionais é um contraponto importante para a tese, na medida em que os rotuladores de imagem das Big Techs estão treinados para classificar figuras e textos associados a produtos de vendas, e fazem uma leitura estritamente visual do objeto e das palavras. Já os classificadores de imagem da tese foram treinados para classificar elementos relacionados às linguagens visual (ilustrativa ou fotográfica) e verbal (tipografia digital ou manual), com a finalidade de decodificar as linguagens visuais emergentes das redes.
Para os propósitos deste artigo, selecionamos a amostra capturada para o Calendário Dissidente: 300.000 imagens coletadas, nas quais 69,8% delas foram marcadas com #MariellePresente. Desse conjunto, escolhemos 83 imagens relacionadas à Marielle que atingiram o limite de 50.000 curtidas em agosto de 2020 – extraídas da biblioteca Instaloader para a linguagem de programação Python. O segundo conjunto consiste em 213.000 imagens postadas no Instagram, com esta mesma hashtag de janeiro de 2019 a agosto de 2020.
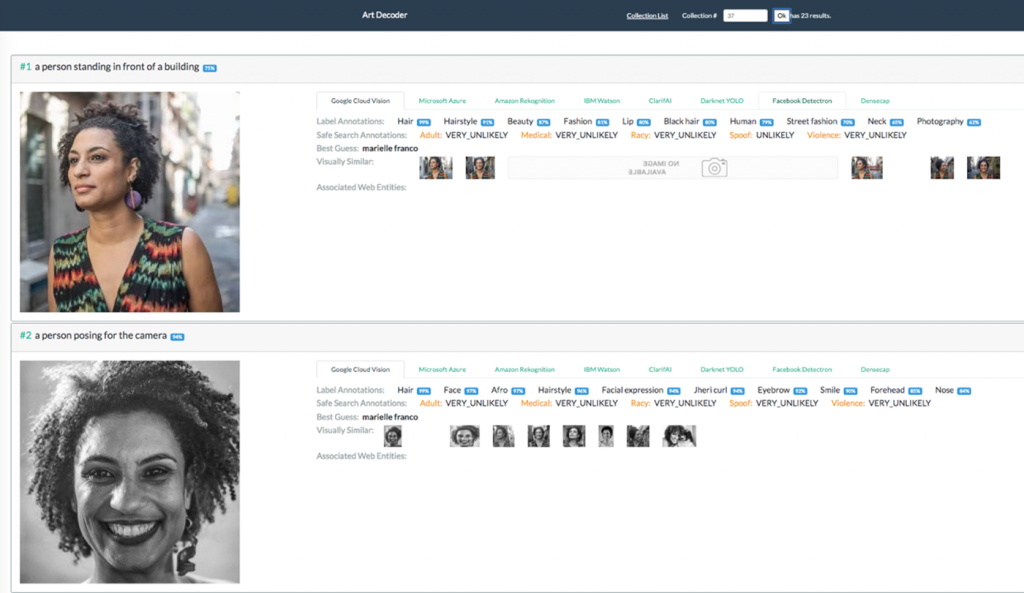
Observamos como essas imagens foram compreendidas pela Google Cloud Vision – ferramenta comercial do Google, treinada a partir de rótulos (labels) focados em geração e negócios para clientes da plataforma. Com base nestas análises de visão computacional, discutimos as ambivalências que o ativismo enfrenta no âmbito capitalista das mídias sociais. E descobrimos que a imagem de Marielle, provavelmente por conta do fenômeno de repetição de sua imagem na dentro e fora das redes, consegue quebrar a invisibilidade do negro na internet. A Google Cloud Vision, passou a reconhecer o rosto de Marielle.
A fotografia abaixo, de autoria de Bernardo Guerreiro, foi feita em 2016 no Complexo da Maré, na época de sua campanha para vereadora do Rio de Janeiro. Depois de sua morte, esta imagem circulou primeiramente via Mídia Ninja e foi replicada inúmeras vezes. É o retrato de Marielle que mais circulou no Instagram e no Google Image, apropriado de diversas formas. Essa imagem, devido à sua ampla circulação, também é uma das únicas reconhecidas pelas IAs da Google Cloud (e tagueada) com o tag “name” Marielle Franco.

Por outro lado, apesar do resultado da visão computacional rotular a figura de Marielle Franco, como melhor aposta, notamos que os rotuladores da Google Cloud Vision classificaram essa imagem icônica de Marielle com as seguintes tags: 99% cabelo; 91% hairstyle; 87% beleza; 81% moda; 80% lábios; 80% cabelo preto; 79% humano; 70% street fashion; 65% pescoço; 62% fotografia, o que comprova que as IAs foram treinadas para identificar objetos específicos que geram tráfego e são metadados para ações comerciais. A tag “humano” está em 7º lugar e a figura da mulher não é identificada pela IA, muito provavelmente por ela ser negra.
As discussões em torno da leitura dessas imagens pelo viés do capitalismo de vigilância contemporâneo podem ser aprofundadas a partir das ponderações de Zuboff (2019). Esse autor, nos alerta sobre o comércio de dados capturados a partir da navegação dos usuários. Essas categorizam e tagueam as imagens com labels específicos, visando os segmentos de seus anunciantes: empresas de cosméticos, automóveis, tecnologia, turismo, setor de alimentação, vestuário etc. Assim, os anúncios passam a ser direcionados aos consumidores, internautas que deixam seus rastros na rede de forma invisível. Ver imagem vigilante.
Não vamos estender essa questão da politização de dados, embora seja um ponto importante para entendermos a complexidade da ecologia das imagens informacionais. Grosso modo, podemos dizer que há uma dicotomia das hashtags ativistas das redes. Se por um lado agregam comunidades e são capazes de engajar multidões acerca de uma luta, conseguindo muitas vezes alterar (ou no mínimo intimidar) o status quo sobre determinados assuntos – como no caso de #blacklivesmatter e #mariellepresente – por outro lado, oferecem dados que podem ser manipulados pelas grandes corporações e permitem, de forma imperceptível ao internauta, a varredura de dados para ações de grupos antagônicos, proclamadores de fake news, além de oferecer informações preciosas para o comércio on-line, principal fonte de renda das grandes Big Techs. Ou seja, quando vemos uma imagem (um metadado) se repetir muitas vezes no nosso feed, essa imagem exposta representa além do ativismo a qual simboliza. Ela é uma imagem cujas tags são potencialmente rentáveis para as grandes plataformas.
Vimos como a imagem-mensagem está atrelada aos acontecimentos das ruas e como o contexto sociopolítico interfere diretamente na produção da imagem, é diretamente proporcional ao engajamento da narrativa de determinada hashtag nas redes. Este agregador de imagens-mensagens dá visibilidade a muitas causas, destaca alguns atores, usuários e produtores de linguagem. E também receptores e mediadores das imagens-mensagens clonadas, apropriadas, remixadas.
A visualização de algumas narrativas como a #mariellepresente, extraídas e analisadas para exemplificar a potencialidade e diversidade das linguagens nas redes a partir da lupa do design gráfico apresenta um recorte dentre as milhares de imagens e aponta como a edição cognitiva limitaria a possibilidade de descobrir artistas emergentes, outros trabalhos e diferentes técnicas.
Entretanto, a visualização com metodologias de IA apresenta agrupamentos de imagens por semelhança visual (no caso do uso da ferramenta t-SNE), que estão longe de representar uma leitura visual das materialidades e linguagens empregadas no post, assim como não conseguem discernir o contexto no qual a imagem foi produzida e veiculada.
Ao verificar a leitura pelos classificadores de imagens das grandes nuvens computacionais, verificamos que esses são programados para ler a imagem a partir do viés cultural de quem treina a máquina para a rotulação de imagens, privilegiando aspectos comerciais e denunciando o colonialismo explícito nas visões computacionais.
A problematização da leitura da #mariellepresente por essas visões computacionais representa um contraponto importante ao fato de a pesquisa propor como desafio metodológico a criação de classificadores de imagens específicos a partir de paradigmas estéticos.
A leitura crítica desses processos institucionalizados pelas nuvens computacionais de empresas como o Google, nos coloca a par da dificuldade da análise de uma amostra volumosa de imagens a partir de critérios contextuais (sociopolíticos e culturais) e estéticos (pela sua configuração formal). Aplicar o uso de scripts de visualização por meio de inteligências artificiais para fins criativos e arquivísticos nos pareceu o caminho mais assertivo para atingir nossos objetivos.
Narrativas desobedientes, dados idem
Os dados não obedecem a nossos comandos e desejos. Eles aferem e apostam em uma média e no padrão de repetições e dados numéricos. Como vimos, muitas vezes os resultados são críticos e confusos, análogos à nossa interpretação que, muitas vezes, não consegue aferir uma única categoria à determinada imagem. Classificar essas imagens compostas de múltiplas linguagens é uma tarefa complexa, que problematiza a linguagem remixada das redes e deixa claro a interdependência entre as inteligências artificiais e os humanos.
Para a máquina e para nós, humanos, a ação de classificar significa encontrar evidências que se repetem e configuram um padrão reconhecível dentro de alguns parâmetros. Ao analisar visualmente os erros dos classificadores, conclui-se que a subjetividade da interpretação da rede neural coincide com as dúvidas da classificação dos editores ao estabelecer os modelos ideais para treinar cada categoria de classificador. [Sidenote: Tema também abordado no artigo A subjetividade da interpretação de imagens pelas inteligências, publicado pela autora da presente tese com Giselle Beiguelman, no livro Inteligência artificial: avanços e tendências, 2021.]
Os modelos de inteligências artificiais, criados especificamente para a análise desse conjunto de imagens, foram programados para ler aspectos, às vezes intangíveis, relacionados às suas composições formais e significados. O léxico da linguagem visual é carregado de significados semânticos que fogem a qualquer classificação maquínica, estandardizada ou padronizada. O repertório cultural atribui valores à imagem lida, por meio de processos de associação que extrapolam a sintaxe visual da composição da imagem. E é justamente esse caráter contextual do olhar que aproxima os erros da classificação da máquina aos erros humanos.
A dúvida e a subjetividade na leitura das imagens são inerentes ao processo, além de presentes nos acertos interpretativos da máquina treinada para este projeto. Treinada e manipulada como uma extensão classificatória altamente escalada e capacitada para reconhecer, selecionar e categorizar diversos tipos de imagens, em grandes quantidades, e em segundos. Os dados inferidos como referência visual já passaram por uma interpretação prévia, foram revisados para servirem como parâmetros estéticos de determinado conjunto de imagens. Essa etapa é crucial e nesse estágio reside toda a responsabilidade e o poder humano em manipular os dados para um fim determinado.
A interdependência entre os classificadores de imagens e as diretrizes dadas pelo seu treinador é um ponto crucial para entender como a subjetividade da interpretação da máquina está relacionada ao nosso repertório cultural, ideológico e, principalmente, ao objetivo principal do editor e pesquisador. Os trabalhos de Paglen (2018), Zer-Aviv (2020) e Moreschi (2020), expostos na Galeria Uso de IA para fins artísticos e curatoriais, explicitam a responsabilidade e poder de decisão do treinador, o homem.
No contexto do desconhecimento do que de fato é arquivado retroativamente pelas empresas detentoras dos dados das nuvens das redes sociais, a construção dos classificadores em questão aponta alguns desdobramentos importantes para o campo do design, da fotografia e da net art no quesito da interpretação e da subjetividade das IAs. Os softwares criados geraram seis rotuladores de imagem, estão com os códigos abertos e poderão contribuir para outras pesquisas no campo.
A constatação da interdependência entre os classificadores de imagens e as diretrizes dadas pelo seu treinador, neste caso um pesquisador e designer gráfico, foi um ponto crucial para entender como a subjetividade da interpretação da máquina está relacionada ao repertório cultural, ideológico e, principalmente, ao objetivo principal do editor e curador das imagens.
As imagens arquivadas pelo rótulo “ilustração digital” estão abertas a novas interpretações, sujeitas a outras categorizações estéticas, na medida em que algumas imagens apresentam uma linguagem remixada, composta por sobreposições de imagens e colagens. Outras, são compostas por desenhos vetorizados, massas de cores que configuram formas e contornos. Essas imagens inspiram novas curadorias e a criação de novas narrativas e outras reinterpretações gráficas.
Com a visualização das classificações, conseguimos aferir o que merece ser arquivado à luz do design gráfico, como uma nova linguagem visual inerente às redes sociais. E como memória gráfica brasileira. Em tempos de “memória da amnésia” e políticas de esquecimento (BEIGUELMAN, 2019), a criação de rotuladores próprios para classificar as imagens-mensagens dissidentes significa a possibilidade do designer de estabelecer critérios do que vale a pena ser lembrado, arquivado e visualizado.
A adesão pela metodologia de aprendizagem de máquina para a criação de rotuladores nos coloca em uma situação peculiar onde a estratégia curatorial apreende novas informações relacionadas às imagens analisadas, a partir dos acertos e dos erros dos modelos neurais. A visualização das imagens pelos modelos informacionais contribui para alguns questionamentos do que vemos e das possibilidades interpretativas acerca da imagem, nem sempre categorizadas em uma única categoria. A interpretação visual das IAs, reconfigurada e “re-representada” pelos modelos visuais do MMD Critic (KIM et al., 2016) nos leva a outras descobertas e indagações.
A estética de banco de dados emerge da superprodução de informações disponíveis no fluxo das redes. A pesquisa aponta o potencial estético da visualização das narrativas visuais pelas inteligências artificiais e a ressignificação dessas narrativas a partir dos dados das redes neurais. Na medida em que ampliamos a análise dos exemplos visuais com o uso de inteligências artificiais, entramos em contato com outras características dessas peças gráficas, objetos materiais.
Ao navegar pelos meses dos calendários de 2019, temos uma boa leitura por meio de imagens, um mosaico de linguagens visuais – ilustrações manuais, imagens documentais apropriadas da grande mídia, ilustrações vetoriais digitais e colagens com linguagens remixadas. Lemos os acontecimentos sociopolíticos por meio de outra linguagem. As imagens produzidas e compartilhadas por muitos formam uma narrativa heterogênea, em termos de linguagem visual, mas uníssona em termos de mensagem. Um jogo de linguagem, participação coletiva, adição, apropriação, trocas afetivas, posições políticas, ativismos relacionados a vários temas. Há uma contaminação de um sentido comum, de algo que nos afeta, gerando um senso de necessidade em participar dessa corrente, produzindo conteúdos gráficos, participando desse jogo de linguagem de ler por imagens.
O propósito de criarmos os experimentos gráficos Calendário Dissidente e o Pantone Político tem o objetivo de dar visibilidade às novas linguagens visuais emergentes das redes por meio de novos formatos curatoriais, a partir de pressupostos críticos em relação ao uso das ferramentas tecnológicas e do uso de IA. A subjetividade interpretativa das máquinas inspira novas investigações em relação ao homem-máquina, além de sugerir um campo abrangente a ser explorado por designers, artistas e pesquisadores da imagem em geral.